As I have mentioned in the last post, I was terribly surprised (and it wasn't the good surprise) when I realised that the Neural modeling fields algorithm by Perlovsky is only some widening of Gaussian mixture model algorithm. So I decided to start with the Gaussian mixture models and then continue by dynamic fuzzy logic, models adding and parameters changing.
What is it all about. You have some data and there could be some patterns(clusters) which you'd like to find. There are several techniques and among them the most favorite is k-means clustering. Gaussian mixture model supose that the data are the result of mixture of some patterns (models, clusters)

and that these models can be described by the gaussian probability distribution function:
There is the same problem as in the k-means clustering, that we don't know how many clusters we should find. So we try different numbers and we must be very cautious not to overfit the data (this could result into the situation where is one model for each data point).
Lets say that we know how many clusters should we await (a priori given number of components). Now we can intialize the centers of gaussians randomly or we can use k-means clustering algorithm to ease the work.
But now it is the hard part. We have to determine the parameters of a mixture. the most widely spread technique is seemingly Expectation-maximization algorithm(EM). EM is of particular appeal for finite normal mixtures where closed-form expressions are possible such as in the following iterative algorithm by Dempster et al. (1977) All the work is about maximizing the log-likelihood function, the likelihood estimation for this problem (similiraty between models and data).
Log-likelihood can be expressed as:

Where theta is a set of models' parameters(centers and covariance matrix), n is a number of datapoints and f is the likelihood between each datapoint and the models.
Using covariance matrix we will compute for each datapoint the probability that it is corresponding to the given model (the likelihood for each datapoint) l.
Further f will mean the probability that the signal X was generated by the model M (so it should sum between the models up to 1). I will use some explanations and equations from the Perlovsky's work:

Now we have to dynamicly change the parameters - maximize them having the computed likelihood function.
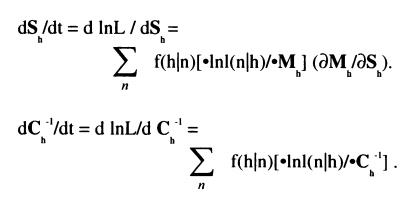
The same dynamic update only with different notation:

Thus on the basis of the current estimate for the parameters, the conditional probability a given observation x(t) being generated from state s is determined for each t = 1, …, m ; m being the sample size. The parameters are then updated such that the new component weights correspond to the average conditional probability and each component mean and covariance is the component specific weighted average of the mean and covariance of the entire sample.
Now we can use these new parameters and iteratively compute likelihood functions for each datapoint and model and compute new parameters...
Main problems which occured during implementation:
1, I know I should know how to multiply the matrices, but when you are in the n-dimensional space, have many different matrices, it can be quite tricky...
2, Covariance matrices - for each model there should be one (because you want to change parameters differently for each model), you can have scalar variance, isotropical model (having numbers only on the diagonal of the matrix) or full variance matrix - I recommend to start with isotropical and then continue to full variance matrix, and....covariance is standard deviation of the data
3, it isn't mentioned everywhere but you have to normalize everything what should be normalized
Ok, ok, but where is the Perlovsky's idea? I will surely describe it more precisely in some further post. But the main idea is to start from some highly fuzzy gaussian model, make it more and more crisp, then add some parameters, and fit the data as well as it is possible. So I'll discuss in the next posts some problems with adding models, changing parameters etc.
Further reading:
Nice explanations about Neural modeling fields, EM algorithm, Mixture models and gaussian probability function can be found on the Wikipedia.
About gaussian mixture models for example:
http://www.ll.mit.edu/mission/communications/ist/publications/0802_Reynolds_Biometrics-GMM.pdf
Very nice master thesis:
http://phd.arngren.com/DL/imm5217.pdf
Perlovsky's work:
book: Perlovsky, L.I. (2001). Neural Networks and Intellect: using model-based concepts. Oxford University Press, New York, NY (3PrdP printing).
some useful articles:
http://www.leonid-perlovsky.com/11%20-%20FDL%20NMNC.pdf
http://www.leonid-perlovsky.com/papers-online.html
Žádné komentáře:
Okomentovat